OpenCL の設定について
CentOS 6.5 と Windows 7 で OpenCL を利用できるようにします。
OpenCL のインストール
CentOS の計算機には、NVIDIA のグラフィックボードが乗っていたので、CUDA をインストールすることで、OpenCL が利用できるようになりました。
Windows 7 には、AMD のチップが乗っていたので、AMD の開発環境をインストールします。
Windows 7 への OpenCL のインストール
AMD の開発環境は、http://developer.amd.com/tools-and-sdks/opencl-zone/amd-accelerated-parallel-processing-app-sdk/ からダウンロードします。ダウンロードしたインストールプログラムを実行すれば、問題なく終了しました。
また、Windows で、C のプログラムをコンパイルするには、Visual Studio 2010 などの開発環境も必要です。
OpenCL のテストプログラム
OpenCL の効果を見るために、行列の掛け算をするサンプルプログラムを作成しました。
512 x 512 のサイズの行列の積を、CPU と GPU を使って計算します。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <CL/cl.h>
/* Maximum number of platforms */
#define MAX_PLATFORM 2
/* Maximum number of devices */
#define MAX_DEVICE 4
/* Kernel source program */
const char* Source = "\n" \
"__kernel void test ( \n" \
" const int n, \n" \
" __global float* a, \n" \
" __global float* b, \n" \
" __global float* c \n" \
" ) \n" \
"{ \n" \
" int idx = get_global_id(0); \n" \
" int col = idx % n; \n" \
" int row = idx / n; \n" \
" int k; \n" \
" float sum = 0.0; \n" \
" if(idx < n * n) { \n" \
" for(k = 0; k < n; k++) { \n" \
" sum += a[col * n + k] * b[k * n + row]; \n" \
" } \n" \
" c[col * n + row] = sum; \n" \
" } \n" \
"} \n" \
"\n";
int main(int argc, char* argv[]) {
float* a; // Matrix a
float* b; // Matrix b
float* c; // Matrix c = a * b
float* d; // Matrix d = a * b
int correct = 0; // No. of correct data
int i,j,k; // For work
clock_t st, et; // Count time
cl_int err; // Error code
cl_uint nplatform = 0; // No. of platforms
cl_platform_id platforms[MAX_PLATFORM]; // Platform id buffer
cl_platform_id platform = 0; // Chosen platform id
cl_uint ndevice = 0; // No. of device
cl_device_id devices[MAX_DEVICE]; // Device id buffer
cl_device_id device = 0; // Chosen device id
size_t buildloglen; // Build log length
char buildlog[2048]; // Build log buffer
size_t worksize = 0; // Global work size
cl_context context; // Context
cl_command_queue queue; // Command queue
cl_program program; // Kernel program
cl_kernel kernel; // Kernel object
cl_mem cla; // Device memory for a
cl_mem clb; // Device memory for b
cl_mem clc; // Device memory for c
int n; // Data size
n = 512; // Data size
worksize = n * n; // Global work size
/* Make data */
a = (float *)malloc(sizeof(float) * n * n);
b = (float *)malloc(sizeof(float) * n * n);
c = (float *)malloc(sizeof(float) * n * n);
d = (float *)malloc(sizeof(float) * n * n);
for(i = 0; i < n; i++) {
for(j = 0; j < n; j++) {
a[i * n + j] = rand() / (float) RAND_MAX;
b[i * n + j] = rand() / (float) RAND_MAX;
c[i * n + j] = 0.0;
d[i * n + j] = 0.0;
}
}
/* Calculate d = a * b by CPU */
st = clock();
for(i = 0; i < n; i++) {
for(j = 0; j < n; j++) {
for(k = 0; k < n; k++) {
d[i * n + j] += a[i * n + k] * b[k * n + j];
}
}
}
et = clock();
printf("CPU[sec]: %f\n", (float)(et-st)/CLOCKS_PER_SEC);
st = clock();
/* Get platforms and choose the first */
err = clGetPlatformIDs(MAX_PLATFORM, platforms, &nplatform);
if(nplatform <= 0) {
printf("ERROR: Invalid number of platforms\n");
return EXIT_FAILURE;
} else {
platform = platforms[0];
}
/* Get devices and choose the first */
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, MAX_DEVICE, devices, &ndevice);
if(ndevice <= 0) {
printf("Choose CPU device\n");
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, MAX_DEVICE, devices, &ndevice);
device = devices[0]; // Choose first cpu device
} else {
device = devices[0]; // Choose first gpu device
}
/* Create context */
context = clCreateContext(NULL, 1, &device, NULL, NULL, &err);
/* Create command queue */
queue = clCreateCommandQueue(context, device, 0, &err);
/* Create program object */
program = clCreateProgramWithSource(context, 1, (const char **) &Source, 0, &err);
/* Build program */
err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if(err != CL_SUCCESS) {
printf("ERROR:clBuildProgram %d\n", err);
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, sizeof(buildlog), buildlog, &buildloglen);
printf("%s\n", buildlog);
return EXIT_FAILURE;
}
/* Create kernel object */
kernel = clCreateKernel(program, "test", &err);
/* Create buffer object and set copy flag */
cla = clCreateBuffer(context, CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR, sizeof(float) * n * n, a, &err);
/* Create buffer object for read */
clb = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(float) * n * n, NULL, &err);
/* Create buffer object for write */
clc = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * n * n, NULL, &err);
/* Enqueue to write to a buffer */
err = clEnqueueWriteBuffer(queue, clb, CL_TRUE, 0, sizeof(float) * n * n, b, 0, NULL, NULL);
/* Set kernel argument */
err = clSetKernelArg(kernel, 0, sizeof(int), &n);
err = clSetKernelArg(kernel, 1, sizeof(cl_mem), &cla);
err = clSetKernelArg(kernel, 2, sizeof(cl_mem), &clb);
err = clSetKernelArg(kernel, 3, sizeof(cl_mem), &clc);
/* Enqueue to run the kernel */
err = clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &worksize, NULL, 0, NULL, NULL);
/* Wait for queue execute */
clFinish(queue);
/* Enqueue to read from a buffer */
err = clEnqueueReadBuffer(queue, clc, CL_TRUE, 0, sizeof(float) * n * n, c, 0, NULL, NULL);
/* Decrement the reference count */
err = clReleaseMemObject(cla);
err = clReleaseMemObject(clb);
err = clReleaseMemObject(clc);
err = clReleaseKernel(kernel);
err = clReleaseProgram(program);
err = clReleaseCommandQueue(queue);
err = clReleaseContext(context);
et = clock();
printf("GPU[sec]: %f\n", (float)(et-st)/CLOCKS_PER_SEC);
/* Validate the results */
correct = 0;
for(i = 0; i < n * n; i++) {
if(abs(c[i] - d[i]) < 0.0000001) {
correct++;
}
}
if((n * n - correct) == 0) {
printf("No difference between CPU and GPU result\n");
} else {
printf("Miss = %d\n", n * n - correct);
}
free(a);
free(b);
free(c);
free(d);
return EXIT_SUCCESS;
}
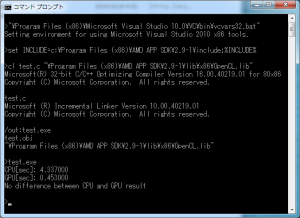
Windows でのプログラムのコンパイル
Windows の Visual Studio の環境で、”コマンド プロンプト” から、コンパイラを起動するには、環境変数の設定等が必要です。これは、Visual Studio の ”VC\bin” の下に、”vcvars32.bat” などのファイル名であります。
また、AMD の開発環境にある OpenCL のインクルードファイルを読み込むための環境変数の設定が必要です。インストールしたバージョンにより、以下のように設定してください。
set INCLUDE=c:\Program Files (x86)\AMD APP SDK\2.9-1\include;%INCLUDE%
これで、以下のようにして、OpenCL のライブラリを読み込みながら、コンパイルが実行できるはずです。
cl test.c "\Program Files (x86)\AMD APP SDK\2.9-1\lib\x86\OpenCL.lib"
Linux でのプログラムのコンパイル
Linux でのコンパイルも、OpenCL のインクルードファイルとライブラリを読み込む必要があるので、以下のようにして、コンパイルします。
cc -I /usr/local/cuda/include test.c /usr/local/cuda/lib64/libOpenCL.so